Speech Emotion Recognition and Deep Learning
disponibile online su ieeexplore under a Creative Commons License
Speech Emotion Recognition and Deep Learning: An Extensive Validation Using Convolutional Neural Networks
Abstract
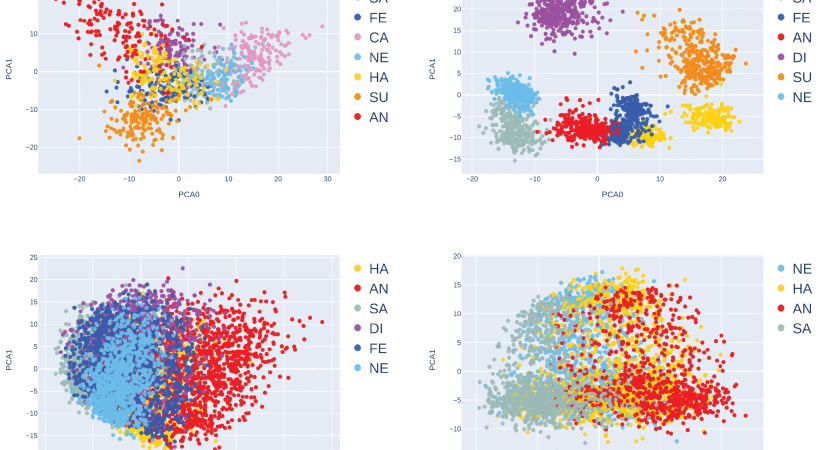
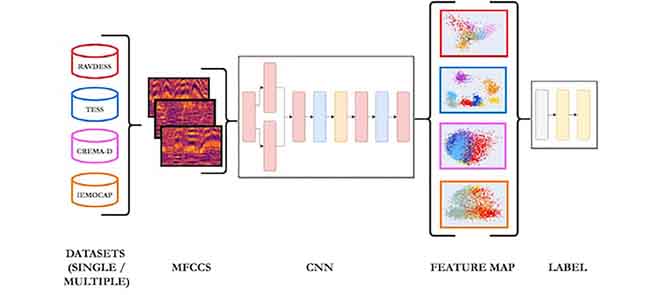
The domain of Speech Emotion Recognition (SER) has experienced a tremendous revolution due to the outbreak of deep learning, which has contributed, as in many other research areas, to a significant boost in terms of model accuracy. SER refers to a branch of Human-Computer Interaction (HCI), which deals with recognizing emotional states from human speech. Although being a thriving field of research, SER still poses several non-trivial challenges, mainly due to the lack of shared best practices and high-quality datasets that can make the developed models suitable for their application in real environments. In this paper, we implement a CNN-based model combined with a Convolutional Attention Block, and conduct a series of experiments involving a selection of four English datasets popularly used for SER applications: RAVDESS, TESS, CREMA-D, and IEMOCAP. After testing the proposed pipeline on individual datasets, achieving a mean accuracy of 83%, 100%, 68% and 63% respectively, we perform an extensive cross-validation between common emotional classes belonging to single datasets or combinations of them, with the aim to investigate the generalization abilities of the extracted features.